I don't use GitHub as my main code repository for the project and I don't use Travis (or Jenkins) for my Continuous Integration. I'm a Gitlab addict and I'm not afraid to say it out loud :). Why should I be, anyway?
Gitlab is an awesome environment which started out as a self-hosted GitHub clone, but now it is so much more that you should definetely check it out. But in this post I don't want to talk about Gitlab as a whole - I'd like to show you some cool stuff that could be done with gitlab-ci and how I currently use it.
Where do I begin?
I'll start with the thing that is my numero uno feature if gitlab-ci (but I realize that it is not unique to this tool). Whole CI definition is included with the code itself in the repository and stored as YAML file. How cool is that, huh?
Having used some of the more old-school automation solutions which separate the work from the code I find this to be so awesome. You most likely won't ever need to ask your build engineer to "Change that make script, pronto" or "Run this on a different docker image, ASAP" (please, don't do that). But this means that gitlab-ci should allow end user to configure a lot of different parameters of a build job, right?
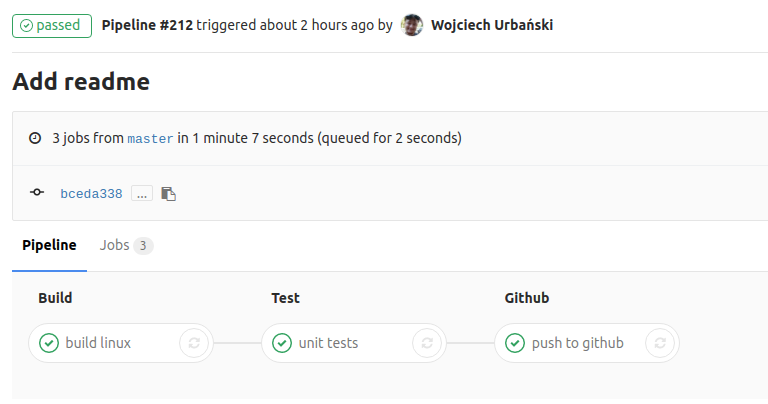
And it does. Let me introduce you to some basic features using example of i-must-go's CI.
Where do I run it?
Let's take a step back. To run a CI, you have to provide some machine to execute the scripts on. This is easy with Gitlab. If you're using gitlab.com, you can use some of the shared runners, which are based on docker. This means that you can use any docker image you want and run your jobs in it. You can even have a specific image for each of the jobs, if that's your preference.
If you are running your own Gitlab instance (or you want to have more control over the runners), you can install gitlab-ci-multi-runner, which allows you to use runner in one of different modes:
- Shell
- Docker
- Docker-SSH
- VirtualBox
- Parallels
- SSH Kubernetes
There are some subtle differences between using runners in those modes, but a good place to read about those is gitlab runner documentation.
How do I create the pipeline?
So, here's how .gitlab-ci.yml looks like:
It's structure is divided into parts defining specifics of the pipeline.
Definition of build stages
The YAML defines whole pipeline of builds to run on each code revision that shows up on the repository. Stages of the pipeline (parts running sequentially) are defined in the first key: stages. Jobs can then be assigned to specific stages.
Build jobs
Each job starts with cloning the repository, restoring the cache (e.g. libraries that would usually be downloaded from the Internet) and copying over any artifacts created in previous jobs. The array under key script contains the work that has to be done on the code. In case of builds, which are run inside docker container, an image can be specified. Jobs are assigned to stages with the key stage (obviously). And you can run some jobs only on specific branches (e.g. push to github will be run only for branch master).
YAML anchors
I use some of the more fun YAML's features: anchors and object merging. This is an alternative for global options set for all build jobs at once. Each of these methods scales differently, depending on structure of your pipeline.
Variables
There are some things which definitions are not shown in the YAML file explicitly, but they are used - variables. Apart from typical use of variables, you can store sensitive data in them by defining them in project's settings. For example, I use them to store SSH key ($GITHUB_SSH_KEY) which will be used in communication with GitHub.
Everything else
This is just a little part of possible build parameters. To read about more of them, it's best to visit the documentaion page.
Finishing touch...
Using tricks shown above, I build and test my code automatically after pushing it to Gitlab and finally (if every other step passes) I push code to github for everyone to see. Neat.
Gitlab's CI is a very powerful tool with a lot of possibilities for customization and I have to say that again - I really love using it in my projects. It allows developers to do all sorts of automation tasks (building, testing and deployments - both automatic and manual) with a lot of flexibility.
And yeah, Gitlab itself is cool as well. Even when they delete their databases. :-)
